Afstandsmeting in de astronomie
This is the essay I wrote in 1979 about the measurement of distances in the cosmos. Afstandsmeting in de astronomie
This is the essay I wrote in 1979 about the measurement of distances in the cosmos. Afstandsmeting in de astronomie

Why pattern matching? In the beginning, computers were solely used for numerical calculations. When the hardware became more powerful in the 1950’s, scientists and scholars devised ways to also mimic higher human faculties in software, such as manipulation of symbolic mathematical formula and translation from one human language to another one. Such efforts could only …
Whereas, during my forming years in the seventies, I was abhorred by computers, in the eighties computers and I found out we could bear each other’s company. From about 1983 I have been kept alife as a software developer by four employers, two commercial and two academic ones. I dare say my background in physics, …

In 1978 I followed a course about the foundations of Quantum Physics. The main theme were the different views on the right interpretation of quantum physics of Einstein on the one hand and Bohr on the other. In 1935, Einstein, together with Podolsky and Rosen, described a thought experiment that showed that quantum physics must be …
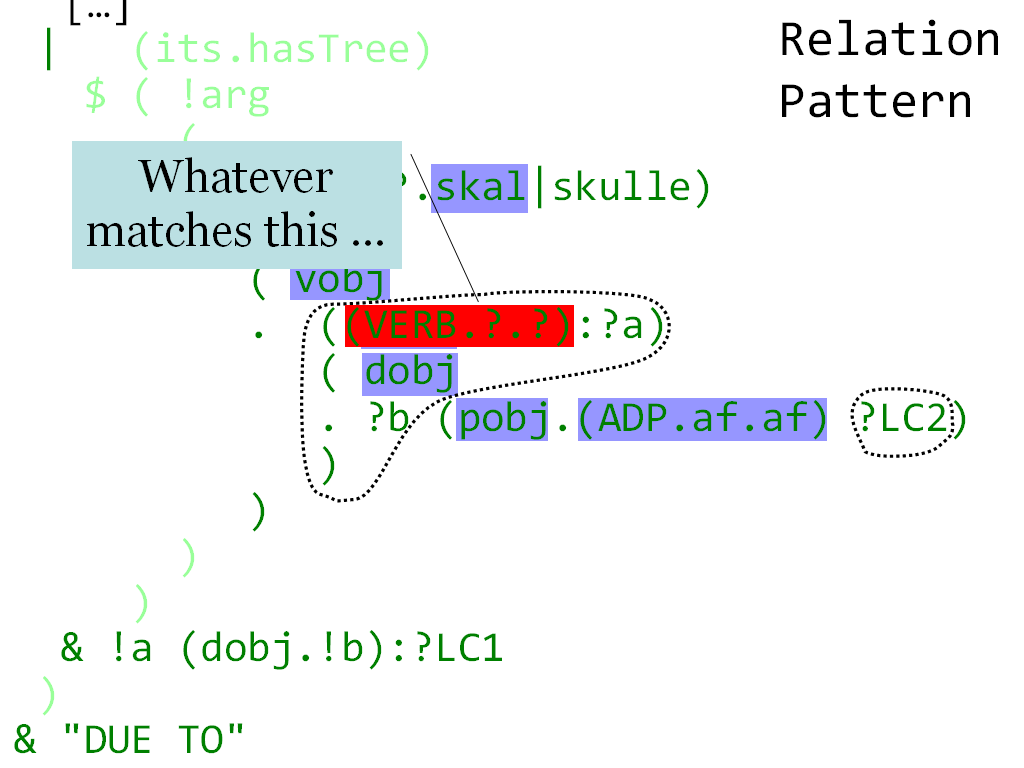
Bracmat is software for analysis and transformation of uncharted and complex data. Pattern matching as a programming language construct is strangely absent or incomplete in popular programming languages. Functional languages (Haskell, Scala, F#, etc.) have tree patterns but lack associative patterns, Perl has associative patterns, but lacks tree patterns, Tom has associative tree patterns, but …